오늘은 리눅스 Ubuntu에 Hadoop을 설치해보도록 하겠습니다.
귀여운 코끼리 로고를 가지고 있는 하둡입니다.

하둡은 분산처리를 도와주는 플랫폼이라고 생각하시면 됩니다.
빅데이터 환경을 구축하기 위해서 필수적인 시스템입니다.
빅데이터 시대가 도래했다!!
요즘 5G 시대가 오면서, 점점 오고가는 데이터들이 많아지고 있습니다.
데이터를 송수신하는데 걸리는 지연시간도 점점 단축되고,
그만큼 다양한 데이터들이 발생하고 어떤 시스템에서는 하루에 몇십억개의 로그들이 찍히고 있는 곳도 있다고 합니다.
이러한 빅(big)데이터를 빠르게 처리하고 저장하기 위해서 빅데이터 프로그래밍이라는 새로운 분야가 개설되었습니다.
우리 집에 있는 컴퓨터로는 빅데이터 프로그래밍을 할 수 있을까요?
절대적으로 못합니다. 하루에 몇억개의 로그를 실시간으로 받아주고, 처리해주다보면,
하루도 채 가지 못해서, 컴퓨터가 병들고, 터질수도...ㅜㅜ
하둡이란?
여러개의 저성능 컴퓨터를 이어붙여서, 각 컴퓨터에 일을 조금씩 부여해주어,
결과적으로는 빅데이터를 처리할 수 있게 만들어주는 시스템.
분산저장과 분산 처리를 지원해줍니다.
분산저장: HDFS(Hadoop Distributed File System의 약자)
분산처리: Hadoop MapReduce(맵리듀스라고 읽습니다.)
## 중요 ##
우분투에 하둡 설치하기
하둡을 설치하기 위한 환경 구축
먼저 우분투의 설치 시스템인 apt-get 을 업데이트 해줍니다.
>> sudo apt-get update

그리고 자바를 설치해주어야겠죠?
아래의 명령어를 실행합니다.
>> sudo add-apt-repository ppa:webupd8team/java
도중에 ENTER 키 한번 눌러주시면 됩니다.

그리고 apt-get 시스템 한번 더 update 해주세요.
>> sudo apt-get update

java 8버전을 설치해주어하는데,
>> sudo apt-get install oracle-java8-installer
의 명령어를 입력하면,

그런거는 없다고 말한다.
왜그런지 찾아보니, JAVA 라이선스 정책이 변경되어서, 수동으로 설치를 해주어야 한다고 한다.
(자동: sudo apt-get install oracle-java8-installer 명령어로 설치하는거를 의미)

blog.naver.com
그래서 아래와 같이 설치해준다.
자바 버전을 관리하는 github 사이트에 들어가서 수동으로 설치진행해준다.
https://github.com/frekele/oracle-java/releases/download/8u212-b10/jdk-8u212-linux-x64.tar.gz
여기서,
1. jdk-8u212-linux-x64.tar.gz 버전에서 마우스 우클릭

2. 주소 링크 복사 클릭
3. 터미널에서 wget + 복사한 주소 붙여넣기(wget 명령어는 링크에 들어가서 해당 파일을 다운로드 하는 리눅스 명령어이다.)
4. Enter 로 설치진행.

5. 잘되고 있쥬?

6. 다운로드 잘 했는지 확인
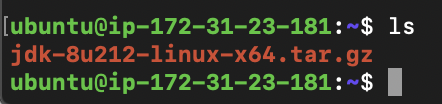
>> ls
명령어 실행하면 jdk-8u212-linux-x64.tar.gz 가 잘 받아진 것을 볼 수 있다.
(ls 명령어는 현재 위치에 있는 파일들의 list를 보여준다. (ls ==> list를 의미하지 않을까?)
7. 압축을 푼다.
>> tar -xvzf jdk-8u212-linux-x64.tar.gz
명령어를 실행(tar 라는 명령어는 tar 로 압축되어 있는 압축파일을 압축하거나, 풀때 사용)

8. 잘 풀렸는지 확인
>> ls
명령어 입력하니, 잘 풀렸다. jdk1.8.9_212 라는 파일이 생김.

9. 해당 파일을 /usr/local 위치로 옮기
>> sudo mv jdk1.8.0_212 /usr/local

10. 잘 옮겨졌다 확인해보니, 잘 옮겨졌다.
>> ls /usr/local

11. 옮겨진 자바를 우분투가 인식하기 위해 환경설정 파일에 등록해준다.
>> sudo vi /etc/profile

위 화면 뜨면, 맨 아래줄에 다음과 같이 추가해준다.
(추가 방법:
1. "esc" 누르고 맨 아래줄에 가서 "a" 키 누르고 입력 활성화시킴
2. 파일 수정하고
3. "esc" 누르고 입력 비활성화시킴
4. ":" 누르고
5. "qw" 누르고 "엔터")
JAVA_HOME=/usr/local/jdk1.8.0_212
CLASSPATH=$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH

JAVA_HOME 이라는 것을 추가해서 앞으로는 우분투가 JAVA를 알아볼 수 있도록 profile에 적어준 것이다.
12. profile 수정하고 나면 리눅스 reboot 전까지는 바로는 적용이 안되서 source 명령어 수행하여 바로 적용시킴

source 명령어 후에 설정한 JAVA_HOME이 잘 뜬다.
13. java -version 확인해서 잘 나오면 성공적으로 우분투에 자바 설치된 것입니다.
>> java -version

드디어 자바 설치 완료!!
이제 다시 apt-get 시스템 업그레이드 해준다./
>> sudo apt-get upgrade

## 우분투 그룹 만들어주고 키 설정 ##
먼저 hadoop 이라는 그룹을 만든다.
>> sudo addgroup hadoop
그리고 해당 그룹에 사용자를 추가한다.
>> sudo adduser --ingroup hadoop hduser
사용자에 대한 비밀번호를 2번 입력받고,
관련 정보들은 입력해준다.(연습용이라면 그냥 enter 치고 넘어간다.)

그리고 sudoers 파일에 사용자를 등록해준다.
>> sudo vi /etc/sudoers

다음의 파일은 중요한 파일이여서 readonly(즉 읽는것만 가능하다고 나온다.)
이것을 해결하기 위해
":" + "q!" (강제종료로 나가서)
아래 링크를 통해
>> sudo bash
>> chattr -i /etc/sudoers
>> chmod u+w /etc/sudoers
입력하고
다시 실행하면 수정가능하다.
>> vi /etc/sudoers
https://datacodingschool.tistory.com/25
os, readonly 파일 수정방법(feat, sudoers 수정)
아래의 코드를 명령창에 실행하면 된다. >> sudo bash >> chattr -i /etc/sudoers >> chmod u+w /etc/sudoers 그 후 수정하면 된다. ex) >> vi /etc/sudoers
datacodingschool.tistory.com

수정하였다.
openssl server 를 설치한다.
>> apt-get install openssh-server
키를 생성해서, 앞으로 들어갈때는 비밀번호 물어보지 않고 들어가게 설정해줌
>> sudo su hduser -> cd -> ssh-keygen -t rsa -P "" -> Enter
>> cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
sysctl.conf 파일을 수정한다.
>> sudo vi /etc/sysctl.conf
맨 아래쪽에 다음 내용 추가
# disable ipv6
l.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable)ipv6 = 1

그 다음 ubuntu 리부트 해준다.
>> sudo reboot
1분 뒤? 다시 켜준다.
## 중요 ##
## 이제 진짜 하둡 설치 ##
1. 노란색 다운로드 들어감

2. 아래 mirror site 클릭

3. https://downloads.apache.org/hadoop/common 클릭하여 들어감

4. hadoop-3점대 버전으로 설치해보겠다.

5. hadoop-3.1.3.tar.gz 파일에서 우클릭하고 링크 주소 복사를 눌러, 주소를 복사한다.

6. wget + 복사한 주소 를 통해 주소가 가리키는 파일을 가져온다.
>> wget 주소

7. 다운로드 받은 hadoop-3.1.3.tar.gz 파일 압축 풀기
>> tar -zxf hadoop-3.1.3.tar.gz

8. 압축 푼 파일을 위치를 옮겨준다.
>> sudo mv 'hadoop-3.1.3' /usr/local/hadoop

9. 아래 명령어도 실행해준다.
>> sudo chown hduser:hadoop -R /usr/local/hadoop
>> sudo mkdir -p /usr/local/hadoop_tmp/hdfs/namenode
>> sudo mkdir -p /usr/local/hadoop_tmp/hdfs/datanode
>> sudo chown hduser:hadoop -R /usr/local/hadoop_tmp/
10. 이제 환경설정 파일을 수정해준다.
>> sudo vi .bashrc
11. .bashrc 파일을 열고 맨 아래에 다음을 추가해준다.

12. hadoop-env.sh 편집해주기
>> cd /usr/local/hadoop/etc/hadoop
>> sudo vi hadoop-env.sh /비밀번호

13. 하둡 관련 파일 수정해준다.
>> sudo vi core-site.xml

>> sudo vi hdfs-site.xml

>> sudo vi yarn-site.xml

template 파일이라고 하둡에서 입문자들을 위해 미리 작성해놓은 구조가 있는데,
아래의 코드가 지금 설치하는 대로 하면 3점대에서는 존재하지 않아서 에러가 날 수도 있다.(그냥 무시)
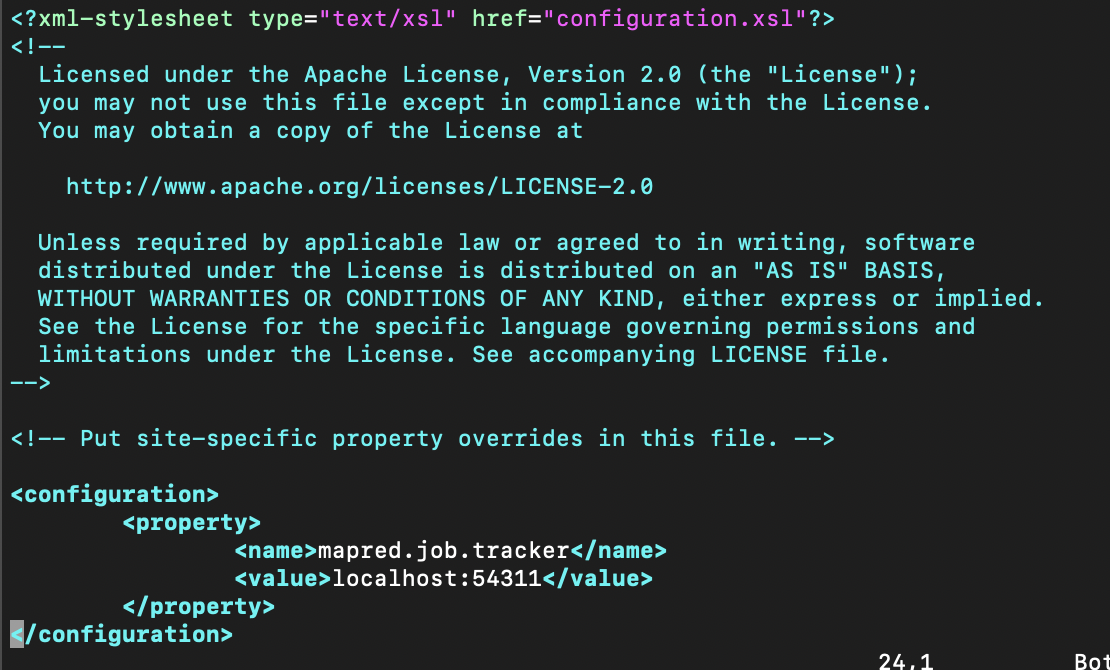
>> cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
>> sudo vi mapred-site.xml
>> cd
>> source ~/.bashrc
>> cd /usr/local/hadoop_tmp/hdfs
## 드디어 하둡 실행 ## (거의 다옴)
각 노드들 켜주는 명령어이다.
>> hadoop namenode -format
>> start-dfs.sh
>> start-yarn.sh
여기까지 하둡 관련 노드들을 실행했고,
잘 실행됬는지 확인하는 명령어를 입력해본다.
>> jps
아래처럼 나오면 성공!!

참고한 블로그: https://coding-factory.tistory.com/60
[Linux] 우분투에서 하둡(hadoop) 설치하기
리눅스 우분투상에서 하둡(hadoop)을 설치해보도록 하겠습니다. 하둡(hadoop)은 빅데이터 환경을 구축하기 위해서 필요한 필수 프로그램입니다. 이번 포스팅에서는 우분투에서 하둡의 설치방법에 대해서 알아보도..
coding-factory.tistory.com
'IT' 카테고리의 다른 글
| 서버 - Spring Tool Suite 4 설치 및 실행 (0) | 2020.04.28 |
|---|---|
| 모델링 - 문장과 문장간의 유사도 검색 모델(Gensim) (0) | 2020.04.28 |
| jupyter notebook 에서 루비 커널 추가하기 (0) | 2020.04.21 |
| jupyter 에서 파이썬 2,3 다중커널 사용하기 (0) | 2020.04.21 |
| MacBook 파이썬 설치하기 (0) | 2020.04.21 |



