안녕하세요
Henry's Algorithm을 운영하는 개발자 헨리입니다.
이번에 과학기술정통부에서 주최하는 2022 오픈소스 컨트리뷰션 아카데미의 대한 기록들을 남겨보려고 합니다.

오픈소스 컨트리뷰션 아카데미란,
주최측에서 선정한 25개의 오픈소스 프로젝트 중 참여자가 관심있는 오픈소스를 하나 선정하여,
해당 프로젝트에 대한 경험이 있는 멘토분과 함께 오픈소스 프로젝트에 기여를 하는 활동입니다!
저는 Apache Zeppelin 오픈소스 컨트리뷰션에 참여하였습니다.
해당 내용에서 진행되는 것들을 모두 기록으로 남기려고 합니다.
오늘은 첫번째 CLI 빌드 입니다.
먼저 빌드하는 자원의 환경입니다.
1. 환경
빌드 자원: 2017 Mac Book Pro
운영 체제: MacOS Monterey 12.3.1
상세 내용은 아래 그림과 같습니다.

그리고 다음으로 Github에서 소스를 다운로드 니다.
2. 소스 다운로드
Apache Zeppelin 프로젝트를 Mac Book Pro의 로컬 공간에 Clone 합니다.
https://github.com/apache/zeppelin
GitHub - apache/zeppelin: Web-based notebook that enables data-driven, interactive data analytics and collaborative documents wi
Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more. - GitHub - apache/zeppelin: Web-based notebook that enables data-driven...
github.com
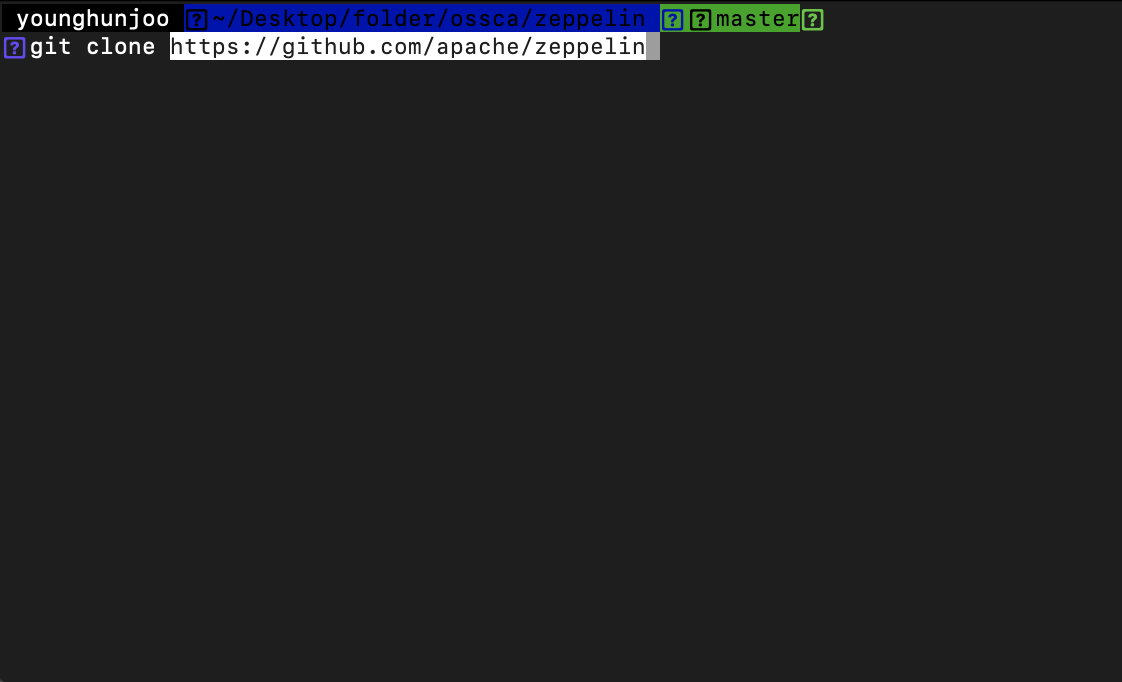
클론이 완료되어, 로컬 공간에 프로젝트가 생성되었습니다.

그리고 세번째는 소스빌드입니다.
3. 소스 빌드
Zeppelin 프로젝트 README.md에서 친절하게 빌드할 수 있는 방법을 명시하고 있습니다.
소스 빌드하는 방법은
1) binary package 설치
2) 다운로드 받은 소스를 빌드
 하이퍼링크 클릭
하이퍼링크 클릭
1. Binary Package 설치
Build from source의 하이퍼링크로 들어갑니다.
https://zeppelin.apache.org/docs/latest/quickstart/install.html
Apache Zeppelin 0.10.0 Documentation: Install
<!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or ag
zeppelin.apache.org
링크를 타고 들어가니 필요한 부분들과 목차를 친절하게 설명해주고 있습니다.
아래의 내용 중 Requirements의 내용에 따라 진행해보겠습니다.

Binary Package 설치에 앞서, 먼저 빌드에 필요한 환경의 요구사항을 살펴봅니다.
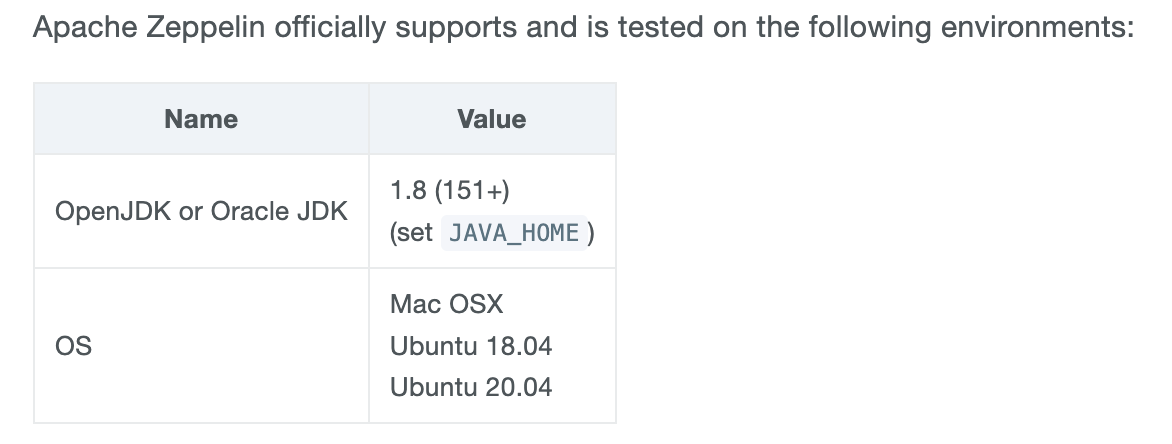
저는 OS는 Mac OSX로 충족이 되었고, JDK는 OpenJDK나 Oracle JDK가 필요합니다.
아래의 명령어로 JDK 버전을 확인해보면, 1.8 버전임을 알 수 있습니다.
java -version
그러나 추후에 maven 실행시 잡혀있는 jdk 버전을 확인해보시려면 아래의 명령어도 한번 확인해주시면 좋습니다
mvn -version
혹은
./mvnw -version

일단 저는 1.8 버전으로 충족되었습니다.
그리고 JAVA_HOME이 잘 정의가 되어있는지 확인이 필요합니다.
JAVA_HOME은 Mac Book에서는 terminal을 실행하여 아래의 명령어로 정의할 수 있습니다.
vi ~/.bash_profile 으로 선언
source ~/.bash_profile 으로 선언된 내용 재부팅 없이 바로 적용
이제 이어서 inary Package를 다운로드할 단계입니다.
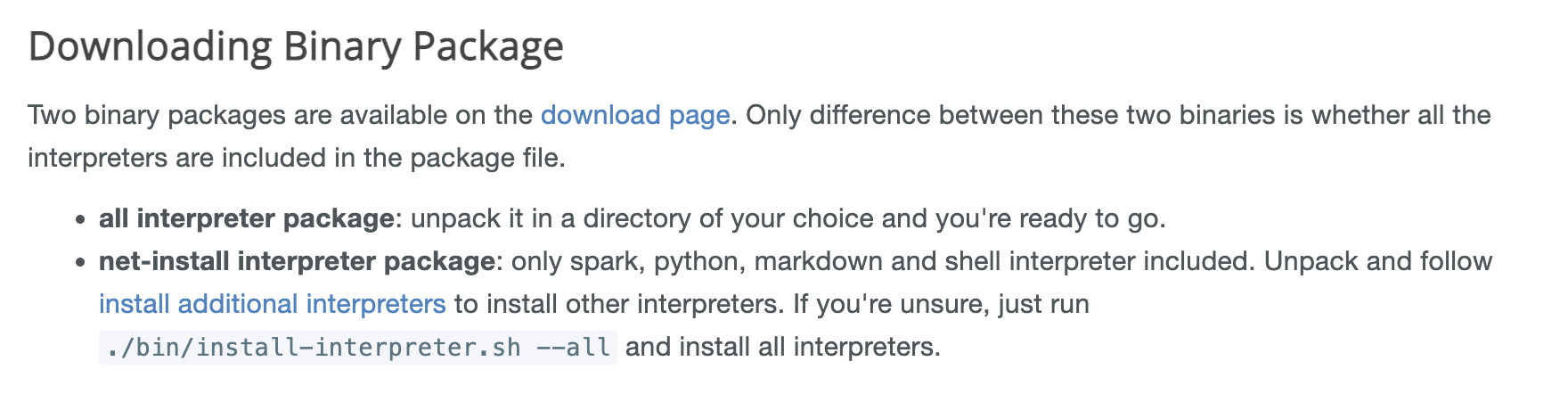
Binary Package는 두 가지가 있습니다.
모든 인터프리터들이 포함되어 있는 패키지와 그렇지 않은 패키지로 구성되어 있습니다.
저는 간단하게 모든 인터프리터가 포함된 패키지로 다운로드하였습니다.
패키지를 다운로드 받았다면 Zeppelin을 소스레벨에서 빌드할 차례입니다.
스크롤을 내려 쭉 내려가니 아래의 텍스트와 하이퍼 링크가 있었습니다.

https://zeppelin.apache.org/docs/latest/setup/basics/how_to_build.html
Apache Zeppelin 0.10.0 Documentation: How to Build Zeppelin from source
<!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or ag
zeppelin.apache.org
먼저 How to Build 하이퍼 링크로 들어갑니다.

페이지에 명시되어 있는 순서대로 진행해보겠습니다.
아까전에도 보았던 빌드하기 위해 필요한 requirements이다.
여기서 확인해줘야 할 부분은 maven 버전이면 되겠네요.

Maven이 설치가 되어있는지 확인해야 합니다.
아래의 명령어로 확인 가능합니다.
mvn -version
혹은
./mvnw -version

저는 Mavn 3.6.3 버전임으로 requirements에 충족되었습니다.
그러나 Zeppelin은 3.8.1 버전만 지원하는 것으로 알고 있기 때문에 변경해주어야 합니다.(기준, 2022-07-12)
mac에서 단순 homebrew로 maven을 설치하시면 버전이 맞지 않을 수 있습니다.
아래 경로에 들어가셔서 tar 파일을 통해 다운로드 받으시고, 압축을 푸신 뒤에, 경로를 환경변수에 잡아주셔야 합니다.
https://archive.apache.org/dist/maven/maven-3/
Index of /dist/maven/maven-3
archive.apache.org
Requirements가 모두 충족되었다면
Zeppelin 소스를 빌드하는 방법은 아래 3가지 단계입니다.
1) 소스를 GitHub에서 클론
2) maven 명령어를 통해 빌드
3) zeppelin 데몬을 실행
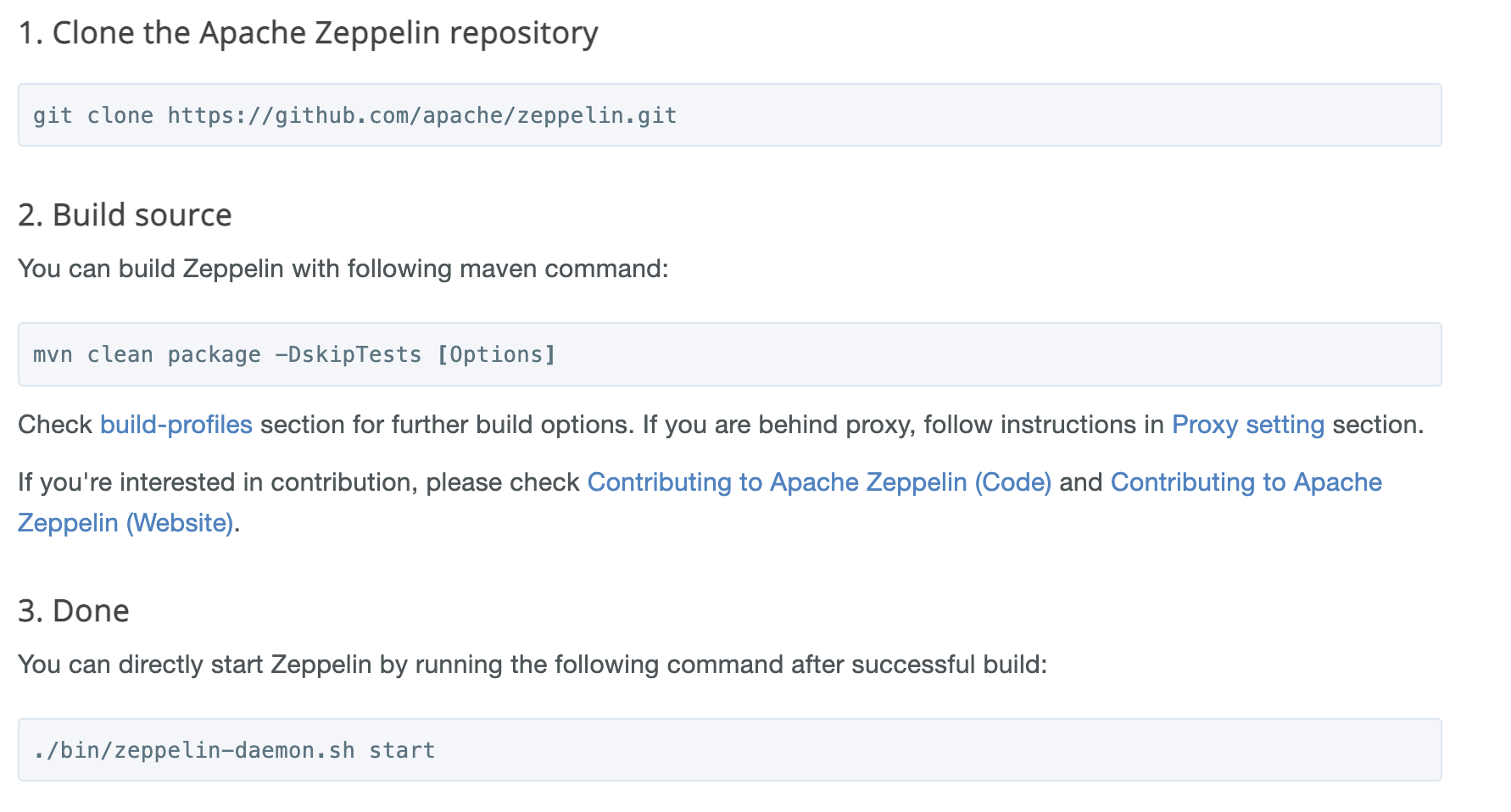
1단계는 완료가 되어있는 상태이기에 바로 2단계로 진행합니다.
아래의 명령어를 실행해줍니다.
./mvnw clean install -DskipTests -Phadoop2 -X

처음에는 Dependency를 다운받느라 시간이 오래걸렸지만, 이내 빌드에 성공했습니다.

빌드 성공 후 zeppelin 데몬을 실행해줍니다.
./bin/zeppelin-daemon.sh start

기본 포트가 8080이여서 브라우저를 열고 localhost:8080으로 접속을 하시면 아래와 같은 화면이 보이실 것입니다. -> 성공

[발생했던 다양한 이슈들]
* 잘못된 버전의 jdk 문제
더보기
위 명령어로 특정 옵션을 주고 빌드해보니, 에러가 발생하였습니다.
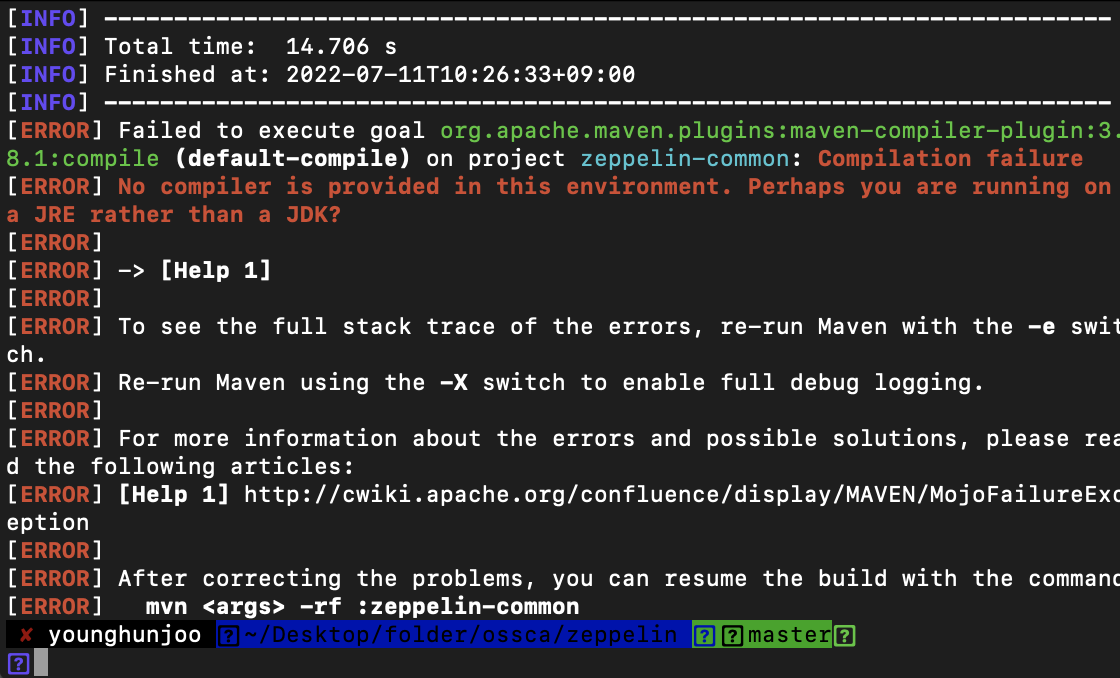
No compiler is provided in this environment 라는 에러입니다.
해당 에러를 구글에 검색해보니, mvn bash에서 현재 jdk 버전이 잘못 설정되어있던 것으로 보여집니다.
저의 맥북에 여러 버전의 jdk가 존재하여 다른 경로의 jdk를 잡고 있었습니다.

아래 명령어로 현재 정의되어 있는 java_home 의 각 java 버전을 확인하였습니다.
usr/libexec/java_home -V

현재 4번째 1.8.0_131로 설정되어 있는데,
3번째 OpenJDK로 변경해줍니다.
방법: 아래의 명령어로 profile 파일 에 JAVA_HOME을 정의.
vi ~/.bash_profile

저는 개인적으로는 보통 맨 밑에다 export로 변수를 추가해줍니다.
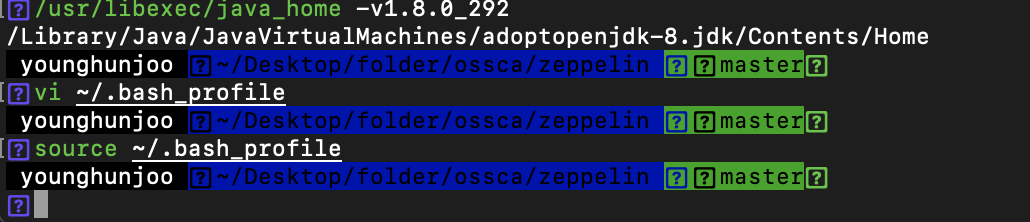
그리고 source ~/.bash_profile로 변경된 환경변수를 바로 적용하였습니다.
그런 뒤 다시 실행해주었습니다.
* 잘못된 버전의 Maven 문제(with, java_home, maven_home)
더보기
이번엔 새로운 에러

이 에러는 구글링 해보니, maven 이 pom.xml 파일을 찾지 못해 발생하는 에러입니다.
MissinProjectException 라고 합니다.
아래 명령어로 pom.xml의 경로를 명시해주어 maven을 실행 가능합니다.
mvn -f path/to/pom.xml <goals> ...

아래의 명령어를 사용하면 빌드가 정상적으로 동작합니다.
sudo ./mvnw -f path/to/pom.xml clean package -Pspark-3.0 -Pspark-scala-2.12 -DskipTests
pom.xml의 경로를 명시하여 빌드를 진행해 줍니다.
경로는 사용자의 환경에 따라 달라지겠죠?
mvnw는 따로 maven이 설치되어 있지 않아도, 프로젝트에 내장된 maven을 사용하고 싶을 때 사용하는 명령어입니다.
 빌드를 진행하며 열심히 다운로드 받는 중이다.
빌드를 진행하며 열심히 다운로드 받는 중이다.
그러나 또 다시 에러가 발생하였습니다.
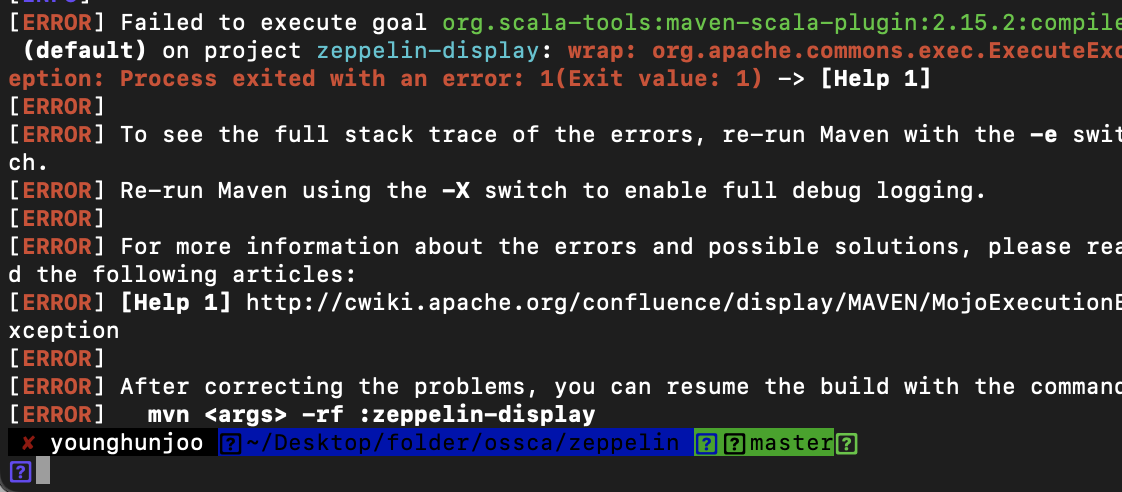
다시 mvnw에 대한 java version을 출력해보니, java 버전이 11버전 이었습니다.
java -version 과 mvn -version을 모두 출력하시면서 jdk 가 동일한지 확인해주면 좋습니다.
vi mvnw
mvnw 소스에 들어가 java_home 경로를 수정하였습니다.
그리고 maven wrapper가 동작하게 해주기 위해 maven wrapper를 설정합니다.
그러나 나중에 알게된 사실인데,
zeppelin 빌드에 있어서 mvnw 프로그램을 별도로 수정할 필요는 없다고 합니다.
* 오류: 기본 클래스 org.apache.maven.wrapper.MavenWrapperMain 문제























