오늘은 Web Programming을 진행할 때 간단하게 디버깅하는 방법을 말씀드리려고 합니다.
웹 공부를 하면서 가장 마주치기 쉬운 문제는 어떤 변수에 값이 들어왔는지 아닌지 확인하는 경우라고 생각합니다.
이런 경우에는 간단하게 아래와 같은 java script 코드를 가지고 해결할 수 있습니다.
<!DOCTYPE html>
<html>
<body>
<h1>JavaScript console.log() Method</h1>
<p>Press F12 on your keyboard to view the message in the console view.</p>
<script>
console.log("Hello world!"); <!-- 바로 여기입니다 -->
</script>
</body>
</html>
윗 부분을 보시면 script라는 태그 안에서 특정 값을 log로 찍어볼 수 있습니다.
이런 코드가 있을 때, 아래와 같이 개발하고 있던 페이지를 로딩하고 F12버튼을 누른 뒤,
상단의 Console 이라는 부분을 보면 로그가 찍히는 것을 발견하실 수 있습니다.
제가 만들고 있는 홈페이지 입니다.(Bootstrap 참조)
이런 방법은 간단한 방법이지만, 때로는 강력하게 작용할 수 있으니, 알아두시면 좋다고 생각합니다!
8. 이 폴더 내에서 runserver 명령어와 manage.py 파일을 통해 개발용 웹 서버를 띄울 수 있습니다.
>> python3 manage.py runserver
Performing system checks...
System check identified no issues (0 silenced).
You have 15 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
October 26, 2018 - 07:06:30
Django version 2.1.2, using settings 'mytestsite.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
9. 아래와 같이 뜨면 성공입니다!
(웹 브라우저를 띄워서 http://localhost:8000으로 들어가면 됩니다.)
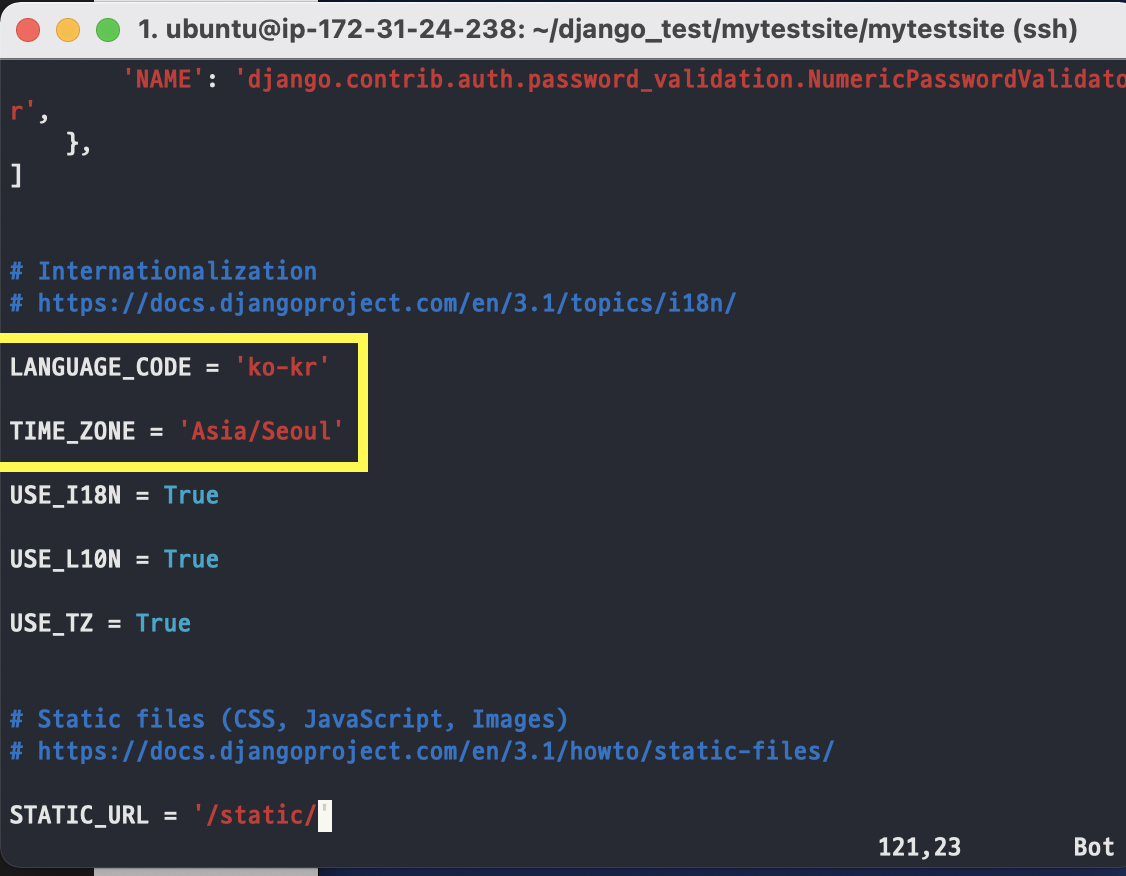
10. 지금까지 컴퓨터에 파이썬과 Django를 설치하면 기본적인 웹 화면을 띄워보았습니다.
장점: 단 방향 통신으로 신호 증폭이 가능하여 거리 제약이 적다.(계속 증폭 시켜주면 되니까)
단점: 노드의 추가/삭제가 불편
망형(Mesh) - 모든 노드가 서로 일대일로 연결된 상태
장점: 특정 노드의 장애가 다른 노드에 영향x / 회선장애에 유연한 대처 가능
단점: 회선 구축 비용이 많이 들고, 새로운 노드 추가 시 비용 부담 발생
5. RAID 레벨에 대해서
RAID란?
Redundant Array of Independent Disk (독립된 디스크의 복수 배열) 이다.
RAID 사용 시 기대효과?
1. 대용량의 단일 볼륨 효과
2. 디스크 I/O 병렬화로 인한 성능 향상(RAID 0, 5 6 등)
3. 데이터 복제로 인한 안정성(RAID 1 등)
RAID는 기계적인 한계로 성능이 느린 하드디스크를 보완하기 위해 만들어진 기술이다.
RAID를 구성하는 디스크의 개수가 많아도 RAID 구성방식에 따라서 성능, 용량이 달라진다.
이 구성방식을 RAID 레벨이라고 부른다.
RAID 0 ~ 6 까지 있지만,
최근에는 RAID 0, 1, 5, 6만 가능하다.
1) RAID 0
출처: https://harryp.tistory.com/806 [Park's Life]
스트라이핑이라고 부른다.
최소 2개의 디스크가 필요하다.(min(N) == 2)
장점: 전체 디스크를 모두 동시에 사용하기 때문에 성능은 N배가 된다. 용량도 N배가 된다.
단점: 하나의 디스크라도 깨지면, 전체 RAID가 깨진다. 즉 안정성은 1/N으로 줄어든다.
성능과 용량은 최대한으로 사용하는 대신, 안정성은 극악이라 할 수 있습니다
2) RAID 1
미러링이라고 부른다.
최소 2개의 디스크가 필요하다.
RAID 1은 모든 디스크에 데이터를 복제하여 기록합니다.
즉, 동일한 데이터를 N개로 복제하여 각 디스크에 저장합니다. 실제 사용 용량 = 디스크의 용량과 같다.
장점: read 시 전체 디스크에서 읽어오기 때문에 빠르다.(단일 디스크의 N배의 성능) // 최대 강점은 안정성이 높다는 것!
단점: write시에 데이터를 복제하기 때문에 시간이 조금 걸린다.
안정성이 중요한 시스템에서 사용 할 수 있겠으나, 비용 문제로 인해 거의 사용하지 않습니다.
3) RAID 2
현재 사용하지 않는 RAID 레벨이다. 최소 3개로 구축 가능함!
bit 단위로 스트라이핑하고, error collection을 위해 Hamming Code를 사용한다.
m+1개의 데이터 디스크와 m개의 패리티 디스크로 구성되는 것 같습니다. (즉 N == (m+1) + m) 그리고 1개의 디스크 에러 시 복구 가능합니다. (2개 이상의 디스크 에러 시 복구 불가능)
4) RAID 3
현재 사용하지 않음, 최소 3개의 디스크 구축 가능
Byte 단위로 스트라이핑하고 error collection을 위해 1개의 패리티 디스크 사용함.
용량 대비 성능이 단일 디스크에 비해 (n-1)배 상승! -1은 패리티 디스크 용도
그리고 1개의 디스크 에러 시 복구 가능합니다. (2개 이상의 디스크 에러 시 복구 불가능)
5) RAID 4
현재 거의 사용되지 않음,
Block 단위로 스트라이핑한다. Error Collection을 위해 1개의 패리티디스크 사용. 용량 및 성능이 N-1 배이다.
Block 단위로 스트라이핑하는 것은 RAID 5,6과 동일하지만, 패리티 비트를 하나의 디스크에 모두 저장해서,
패리티 디스크 사용량이 높아져 패리티 디스크의 수명이 줄어든다.
RAID 4의 단점을 개선시킨 것이 RAID 5 입니다.
6) RAID 5
제일 사용빈도가 높은 RAID 레벨이다. 디스크 최소 3개 필요
Block 단위로 스트라이핑하고, error collection을 위해 1개의 디스크에 패리티 비트를 저장하는데, 매번 다른 디스크에 저장한다.
성능은 단일 디스크의 N-1배이다.
1개의 디스크 에러시 복구 가능(2개 이상부터 불가능)
RAID 0에서 성능, 용량을 조금 줄이는 대신 안정성을 높인 RAID Level이라 보시면 됩니다.
7) RAID 6
RAID 5레벨보다 성능, 용량을 줄이고 안정성을 택한 것. 최소 4개로 구축 가능
Block 단위로 스트라이핑하고, error collection을 위해 매번 2개의 패리티 비트를 다른 디스크에 저장한다.
성능은 단일 디스크의 N-2배이다.
그리고 2개의 디스크 에러 시 복구 가능합니다. (3개 이상의 디스크 에러 시 복구 불가능) 조금 더 안정성을 높여야 하는 서버 환경에서 주로 사용합니다.
8) Nested RAID(중첩 RAID)
여러가지 조합해서 만듬.
6. 다중 스레드
장점:
1) 각 스레드가 속한 프로세스의 메모리를 공유하므로 시스템 자원의 낭비가 적다.
2) 하나의 스레드가 작업을 할 때, 다른 스레드가 별로 작업을 할 수 있어서 사용자와의 응답성도 높다.
단점: 한 스레드에서 문제가 발생하면 전체 프로세스에 영향이 미칠 수 있다.
각 스레드가 서로 교체될때, 문맥교환(Context Switching)이 발생한다. 오버헤드 증가. 그러나 프로세스만큼은 아님.
오히려 많은 양의 단순한 계산은 단일 스레드가 더 성능이 좋을 수 있다.
* 가비지 컬렉터
데몬 스레드를 사용하는 가장 대표적인 예이다.
할당한 메모리 중 더 이상 사용하지 않는 메모리를 자동으로 찾아주어 해제하는 역할을 한다.
보통 가비지 컬렉터가 동작하는 동안, 프로세서가 일시적으로 중단되어 필연적으로 성능 저하가 온다.
7. OSI 7계층
물리: 통신 케이블을 통해 전기 신호를 사용하여 비트 스트림을 전달(데이터 종류나 에러 확인은 하지 않는다.)
데이터링크: 네트워크 계층에서 받은 데이터를 프레임(frame)이라는 논리적인 단위로 구성하고 전송에 필요한 정보를 덧붙여 물리 계층으로 전달한다. 물리계층의 데이터 전송 시 오류 감지 역할(오류 발생하면 재전송)
네트워크: 전송 데이터를 목적지까지 경로를 찾아 전달하는 역할(라우팅 작업 이루어짐)
전송: 데이터를 전송하고, 전송 속도를 조절하고, 오류 발생한 부분은 다시 맞춰주는 역할(TCP 프로토콜을 사용하게 됨) (데이터 전송 단위: TCP: Segment, UDP: Datagram 이다.)
세션: 전송하는 두 종단 프로세스 간 접속(session)을 설정하고, 유지하고 종료하는 역할을 한다.(TCP/IP 세션을 만들고 없앰)
표현: 전송하는 데이터의 표현 방식을 관리하고 암호화하거나 데이터를 압축하는 역할을 한다.(인코딩, 디코딩 이루어짐)
응용: 사용자를 위한 인터페이스 지원
8. 캐시 기억장치 교체 알고리즘
1. LRU: 가장 오랫동안 사용되지 않은 페이지 교체
2. FIFO: 가장 오래된 페이지 교체함
3. LFU(Least Frequently used): 참조 횟수가 가장 작은 페이지 교체
4. Random: 사용횟수와 무관하게 임의로 블록을 교체함
5. Optimal: 가장 오랫동안 사용되지 않을 페이지 교체(구현 불가능, 다른 알고리즘과 비교 연구 목적)
6. MFU(Most Frequently Used): LFU 의 반대로 참조 횟수가 가장 많은 페이지 교체
9. 공개키 암호화 vs 비공개키 암호화
공개키 암호화: 공개키와 비밀키가 존재(공개키는 누구나 알 수 있지만, 그에 대응하는 비밀키는 키 소유자만 알 수 있다.)
-> 이 방식에서 핵심은공개키를 통해 암호화(데이터 보안 중점)한 것은개인키를 통해 복호화할 수 있고개인키를 통해서 암호화(인증 과정에 중점 -> 데이터 제공자의 신원이 보장됨)한 것은공개키를 통해서 복호화할 수 있다는 것이다.
공개키 암호와의 대표적인 알고리즘은 데이터 암호화 표준(Data Encryption Standard)이다.
비공개키 암호화: 동일한 키로 암호화, 복호화를 동시에 할 수 있는 방식
비밀키 암호화는 암호화와 복호화 과정에서 서로 다른 키를 사용하는 비대칭 암호화(asymmetric encryption)이다.
공개키 암호화가 비공개키 암호화보다 느리다.(비공개키가 더 빠름)
10. 세마포어와 뮤텍스
세마포어(semaphore): 공유된 자원의 데이터를 여러 프로세스가 접근하지 못하도록 막는 것
뮤텍스(Mutex): 공유된 자원의 데이터를 여러 스레드가 접근하지 못하도록 막는 것
* Critical Section이란?
OS에서 Critical Section은 아주 중요한 부분이다.
다중 프로그래밍 운영체제에서 여러 프로세스가 데이터를 공유하고 있을 때, 각 프로세스에서 공유 데이터를 액세스하는 프로그램 코드를 가리키는 말이다.
11. 이진 트리
완전 이진 트리: 마지막 레벨을 제외한 모든 노드들이 꽉 차 있고, 마지막 레벨은 왼쪽부터 마지막 노드까지 차례대로 차있는 상태
포화 이진 트리: 마지막 레벨까지 꽉 채워진 상태
이진 트리 순회 종류
1) 전위 순회: 뿌리 -> 왼쪽 -> 오른쪽(깊이 우선 느낌)
2) 중위 순회: 왼쪽 -> 뿌리 -> 오른쪽
3) 후위 순회: 왼쪽 -> 오른쪽 -> 뿌리
4) 층별 순회: 뿌리부터 층별로 순회(너비우선 느낌)
12. 프로세스 스케쥴링(비선점 - 빼앗지 않음, 선점 - 빼앗음)
비선점:
1) FCFS(First Come First Serve Schedule): 비선점, CPU 를 먼저 요청한 프로세스가 먼저 CPU 를 배정 받는 스케줄링 방법이다.
2) SJF: 비선점형, 실행시간이 짧은 작업(프로세스)부터 처리하므로 평균 대기 시간이 FCFS보다 짧다.
선점:
1) Round-Robin: 우선순위가 적용되지 않는 단순한 선점형 방식이다.
2) 다단계 큐(Multi-level Queue): 우선순위에 따라 준비된 큐 여러개를 사용하는 방식이다.
우선순위가 낮은 하위 단계의 프로세스가 실행중이어도, 우선순위가 높은 단계의 프로세스가 들어오면 CPU 빼앗김
3) SRT(Shortest Remaining Time): CPU 할댱량이 적은게 들어오면 그거 먼저 빠르게 처리함
* 프로세스 상태
생성 - 준비 - 실행 - 대기 - 종료
13. TCP/IP 프로토콜 스택이란?
4개의 계층으로 나뉨(응용, 전송, 네트워크, 데이터링크)
데이터링크: LAN,WAN, MAN과 같은 네트워크 표준과 같은 프로토콜을 정의한다. 두 호스트의 물리적인 연결의 표준을 담당함
네트워크: 물리적 연결 완료 후 경로 설정 단계. 경로는 비 연결적이다. 일정한 경로를 제공하지 않고, 중간에 경로가 바뀔 시 데이터 손실 발생할 수 있음. - 오류 발생에 대한 대비가 되어있지 않다.
전송: 두 호스트간 데이터 송/수신 방식에 대한 약속(TCP/UDP) 결정. TCP는 보내고 받았는지 확인하지만, UDP는 보내기만 함.(확인없음)
응용: 클라이언트와 서버간의 데이터 송수신에 대한 약속들
* 아래는 각 계층 별 주요 프로토콜
14. 갖가지 법칙들
1) 무어의 법칙: 인텔 공동 창립자인 고든 무어가 말한거, 2년마다 칩에 집적할 수 있는 트랜지스터 수가 2배씩 증가함
2) 암달의 법칙: 암달의 저주라고도 불림, 컴퓨터 일부를 개선할 때, 전체적으로 얼만큼의 성능 향상이 일어나는지 계산.
3) 구스타프슨의 법칙: 컴퓨터 과학에서 대용량 데이터 처리는 효과적으로 병렬화할 수 있다.
4) 폰노이만 아키텍쳐: 컴퓨터 설계 관점 분석할 때, 사용되는 구조.(프로그램 내장 방식의 컴퓨터)
출처: https://blog.naver.com/with_msip/221981730449
폰노이만 이전(애니악 시절) 1+1 계산 시에는 직접 전선을 뺏다가 껴야하는데, 폰노이만 구조의 컴퓨터는 CPU라는 프로그램이 안에 내장되어 있어서 바로 계산 가능.
5) 리틀의 법칙: 프로세스의 안정상태에서의 재고와 산출율 그리고 흐름 시간의 상관관계를 나타낸 법칙, IT에서는 성능평가에 사용됨.
암달의 법칙은 Latency에 기준, 구스타프슨은 Throughput에 기준을 둠.
15. 슈퍼스칼라란?
한 프로세스 사이클 동안에 하나 이상의 프로세서를 실행시킬 수 있는 프로세서 아키텍처를 의미한다.
16. 분기 예측 기법이란?
다음 실행될 조건문이 어느 곳으로 분기할 것인지 확실히 알게 되기 전에 예측하는 CPU 기술
17. VLIW란?
VLIW(Very Long Instruction Word)는 명령어를 여러개 처리 할 수 있는 방식으로, 동시에 여러 명령어를 실행할 수 있도록 하는 연산 처리 기술중 하나이다.
출처: http://wiki.nex32.net/%EC%9A%A9%EC%96%B4/vliw
18. SIMD란? - 하나의 명령어로 여러개의 데이터를 한번에 처리하는 기법이다.
SIMD란 Single Instruction Multiple Data의 약자로, 하나의 명령어로 여러개의 데이터를 한번에 처리하는 기법입니다. 일반적인 프로그램의 경우 대부분 SISD(Single Instruction Single Data)으로 구현되어 있고, 이것은 기본적인 폰노이만 컴퓨터가 사용하는 방식입니다. 하지만 동영상 인코딩, 그래픽 렌더링 등의 작업에 SIMD를 적용하였을 때는 성능적으로 큰 이득을 취할 수 있습니다.